Saya Berhenti Bayar AWS Buat Mantau Server, Bikin Dashboard Sendiri Aja

Beberapa waktu lalu saya nulis soal gimana saya mangkas tagihan cloud dari $500 ke $50 sebulan dengan pindah dari AWS ke beberapa server kecil di Hetzner. Banyak yang balas dengan pertanyaan yang sama, dan ini pertanyaan bagus:
"Oke, tapi kalau udah cabut dari AWS, gimana lo tau server lo masih hidup? Kan udah nggak ada CloudWatch."
Pertanyaan yang sah. Di AWS, mantau server itu sesuatu yang tinggal lo bayar. Ada layanan namanya CloudWatch yang ngumpulin semua angka, gambarin grafiknya, dan teriak ke lo kalau ada yang rusak. Jalan, dan lo nyaris nggak perlu mikir. Tapi dia juga nongol di tagihan tiap bulan, dan makin banyak yang lo pantau, makin mahal.
Jadi waktu saya cabut dari AWS, saya harus jawab pertanyaan itu sendiri: gimana caranya tetap ngawasin semua tanpa bayar orang lain buat ngelakuinnya?
Ini cerita soal apa yang saya bangun sebagai gantinya. Dan jujur, hasilnya malah lebih enak dari yang dulu. 😄
Apa yang Sebenarnya Perlu Saya Lihat
Sebelum install apa-apa, saya tulis dulu apa yang sebenarnya saya pedulikan. Bukan yang keren-kerenan, cuma yang perlu saya tau biar bisa tidur tenang.
Intinya cuma tiga hal:
- Servernya sehat nggak? CPU, memori, disk, jaringan. Hal-hal dasar yang ngebosenin.
- Aplikasinya jalan nggak? Bukan cuma "servernya nyala", tapi "aplikasinya beneran ngelayanin orang tanpa lempar error".
- Pas ada yang rusak, saya tau cepet nggak? Bukan besok. Sekarang, di HP.
Udah, itu aja. Tiga pertanyaan. Semua yang saya bangun cuma buat jawab tiga itu, nggak lebih.
Tools yang Saya Pakai (dan Fungsinya Masing-masing)
Nah di bagian ini biasanya orang langsung pusing, soalnya namanya serem-serem. Padahal nggak. Saya jelasin satu-satu pakai bahasa manusia, bukan bahasa brosur.
- Node Exporter — program kecil yang nempel di tiap server dan baca kondisinya. CPU, memori, disk, jaringan. Kerjaannya cuma satu: ngukur mesin terus kasih angkanya ke siapa pun yang nanya.
- Prometheus — si pengumpul. Tiap beberapa detik dia keliling nanya ke tiap Node Exporter "eh, angka lo berapa sekarang?" terus dicatat. Anggep aja satpam yang keliling bawa papan jalan, seharian, terus-terusan.
- Promtail — ide yang sama kayak Node Exporter, tapi buat log, bukan angka. Dia ngintipin file log di tiap server terus ngirim tiap barisnya ke satu tempat terpusat.
- Loki — tempat semua log itu mendarat. Ibarat mesin pencari buat log. Daripada SSH ke server terus melototin file teks, saya tinggal ketik kata kunci dan dia tarik persis yang saya cari dari semua server sekaligus.
- Prometheus + Loki barengan = angkanya dan lognya ada di satu tempat.
- Grafana — wajah dari semuanya. Dia ambil semua yang dikumpulin Prometheus sama Loki terus diubah jadi dashboard dan grafik yang lo lihat beneran. Ini layar yang saya buka tiap pagi sambil ngopi.
Jadi alurnya simpel: program kecil di tiap server ngukur, dua pengumpul ngumpulin semuanya, terus Grafana gambarin yang cakep. Bagian terbaiknya? Semua ini gratis dan open source. Nggak ada biaya per metrik, nggak ada tagihan kaget.
Dan ini detail yang saya suka dari artikel sebelumnya: ini bahkan nggak saya jalanin di server produksi. Semuanya numpang di server "mainan" yang murah, si server cadangan. Server produksi tinggal kirim datanya ke situ. Jadi mantau semuanya itu praktis nggak nambah biaya sama sekali.
Dashboard Pagi Hari
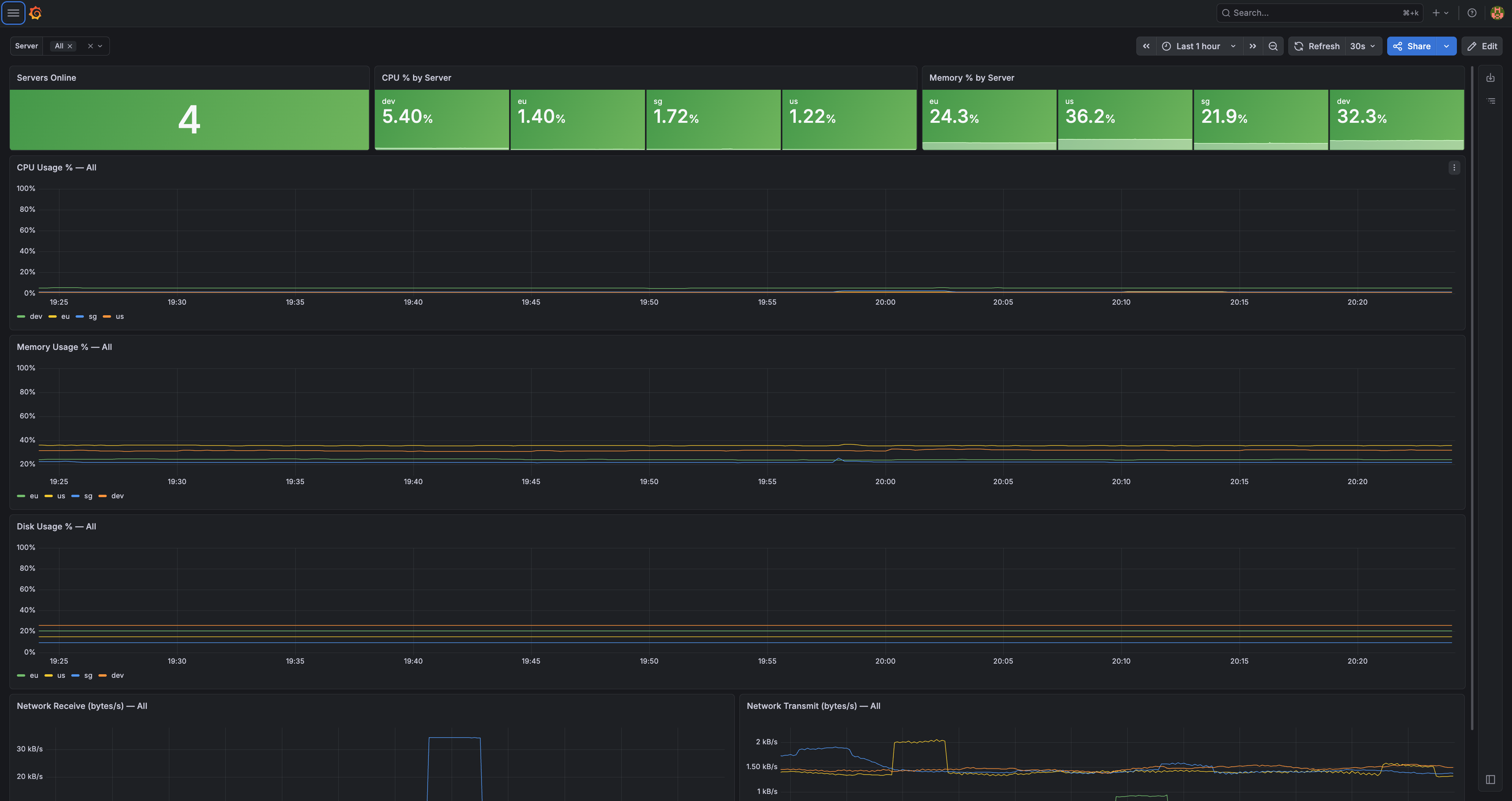
Ini layar yang pertama saya buka. Sekali lirik, saya langsung tau seluruh dunia saya baik-baik aja apa nggak.
Bacanya dari kiri ke kanan. Servers Online: 4 — semua server nyala. Terus CPU sama memori per region, adem semua di angka rendah. Di bawahnya, grafik dari waktu ke waktu buat CPU, memori, disk, dan jaringan.
Justru tujuan layar ini biar saya nggak perlu baca teliti. Kalau semua hijau dan garisnya datar rendah, saya tutup tab-nya dan lanjut hidup. Angkanya baru penting kalau dia berhenti ngebosenin.
Satu layar ini udah gantiin sebagian besar fungsi CloudWatch dulu, dan dia nunjukin semua region sekaligus dalam satu waktu, sesuatu yang di CloudWatch selalu bikin ribet.
Pas Mau Ngulik Lebih Dalam
Kadang dashboard simpel aja nggak cukup. Misal aplikasinya kerasa agak lemot dan saya mau tau kenapa. Nah di situ saya buka tampilan detailnya.
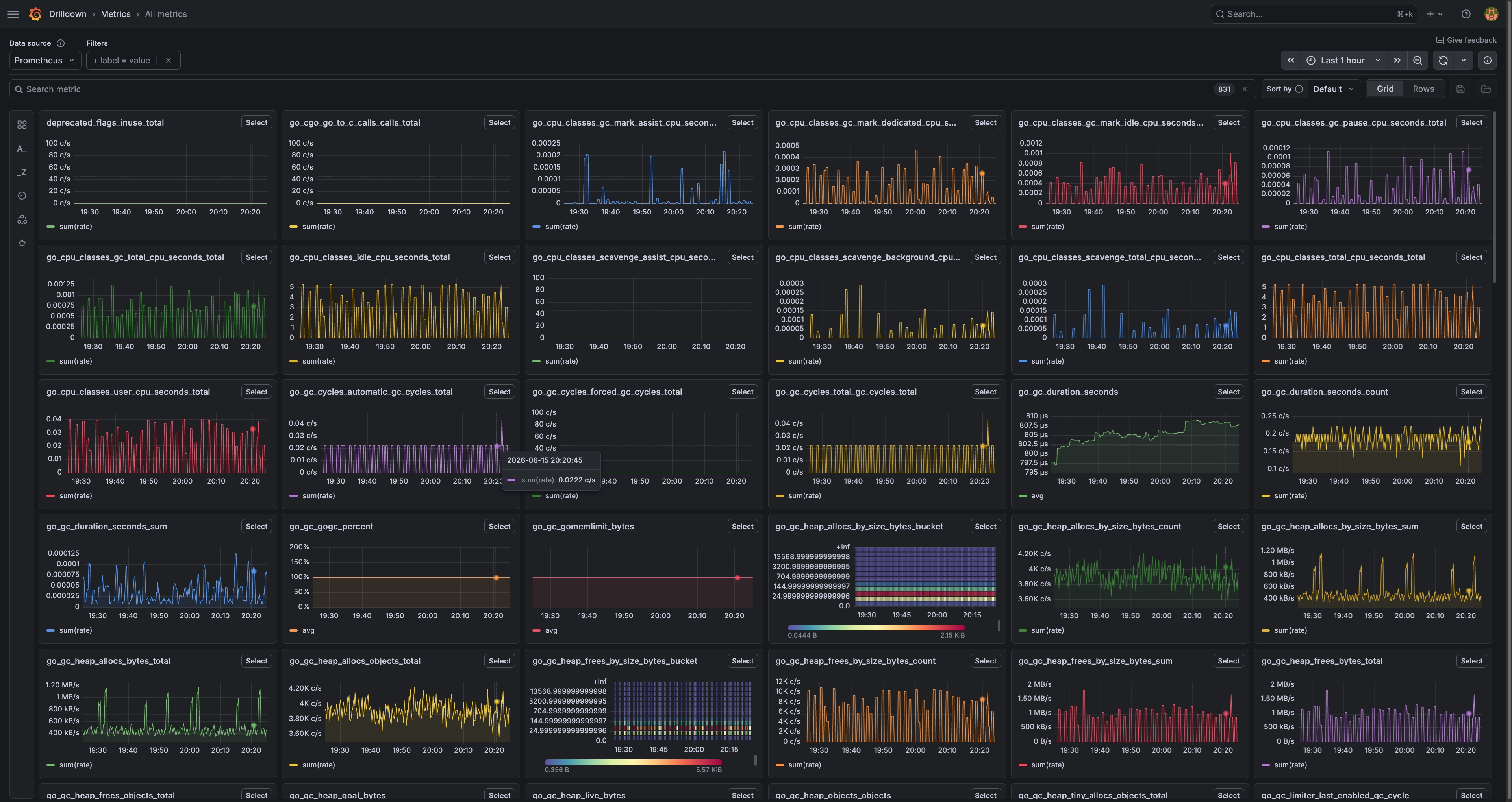
Iya, kelihatannya kayak kokpit pesawat. 😅 Ini semua metrik yang saya kumpulin, ditempel di satu dinding. Garbage collection, memory pool, jumlah request, sampai isi dalem aplikasinya.
Layar ini nggak saya lihat tiap hari. Nggak ada yang harus gitu. Ini layar buat "ada yang aneh nih, gue selidikin". Pas dashboard simpel ngasih tau ada sesuatu yang nggak beres, layar ini yang ngasih tau apa masalahnya. Dashboard simpel itu alarm asap; yang ini halaman yang saya buka setelah alarmnya bunyi.
Bagian yang Beneran Penting: Diteriakin
Ini yang jarang ada yang kasih tau soal dashboard: dashboard cuma berguna kalau lo lagi ngelihatin.
Dan jam 3 pagi saya nggak ngelihatin. Saya tidur. Jadi dashboard cakep doang itu nggak ada gunanya buat satu momen yang paling penting, momen pas ada yang rusak sementara saya nggak ngawasin.
Makanya jantung asli dari setup saya itu bukan grafiknya. Tapi alert-nya.
Saya bikin beberapa aturan simpel. Sengaja nggak macem-macem:
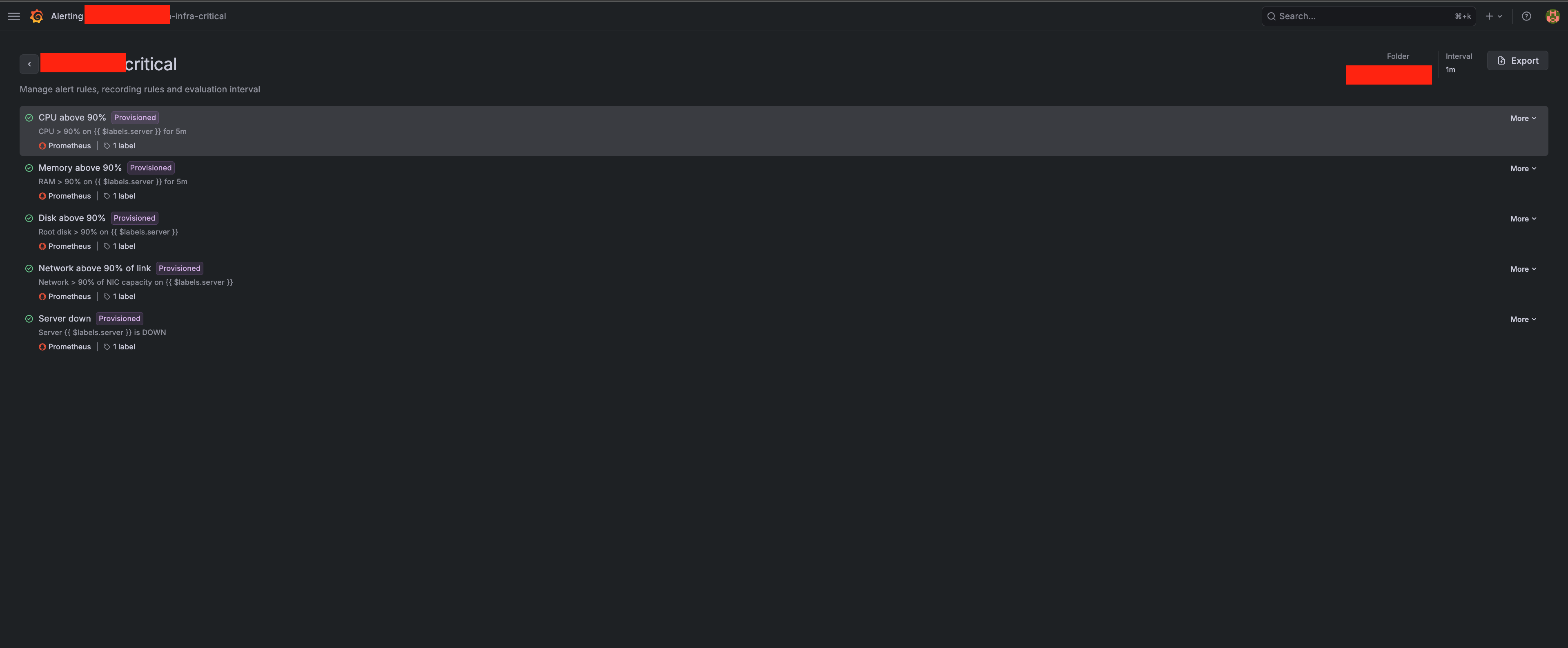
- CPU di atas 90% selama 5 menit nonstop
- Memori di atas 90% selama 5 menit
- Disk di atas 90%
- Jaringan di atas 90% dari kapasitas
- Server mati — yang paling gede. Servernya udah nggak nyaut sama sekali.
Perhatiin bagian "selama 5 menit" itu. Saya nggak mau dipingin tiap kali CPU naik dua detik, itu wajar, itu cuma server lagi kerja. Saya cuma mau tau kalau ada yang jelek cukup lama sampai beneran jadi masalah. Kalau nggak gitu, alert-nya banyak banget sampe nggak guna, dan ujungnya semua diabaikan, termasuk yang beneran penting.
Dan pas satu aturan kepicu, alert-nya langsung masuk ke chat saya, di HP:
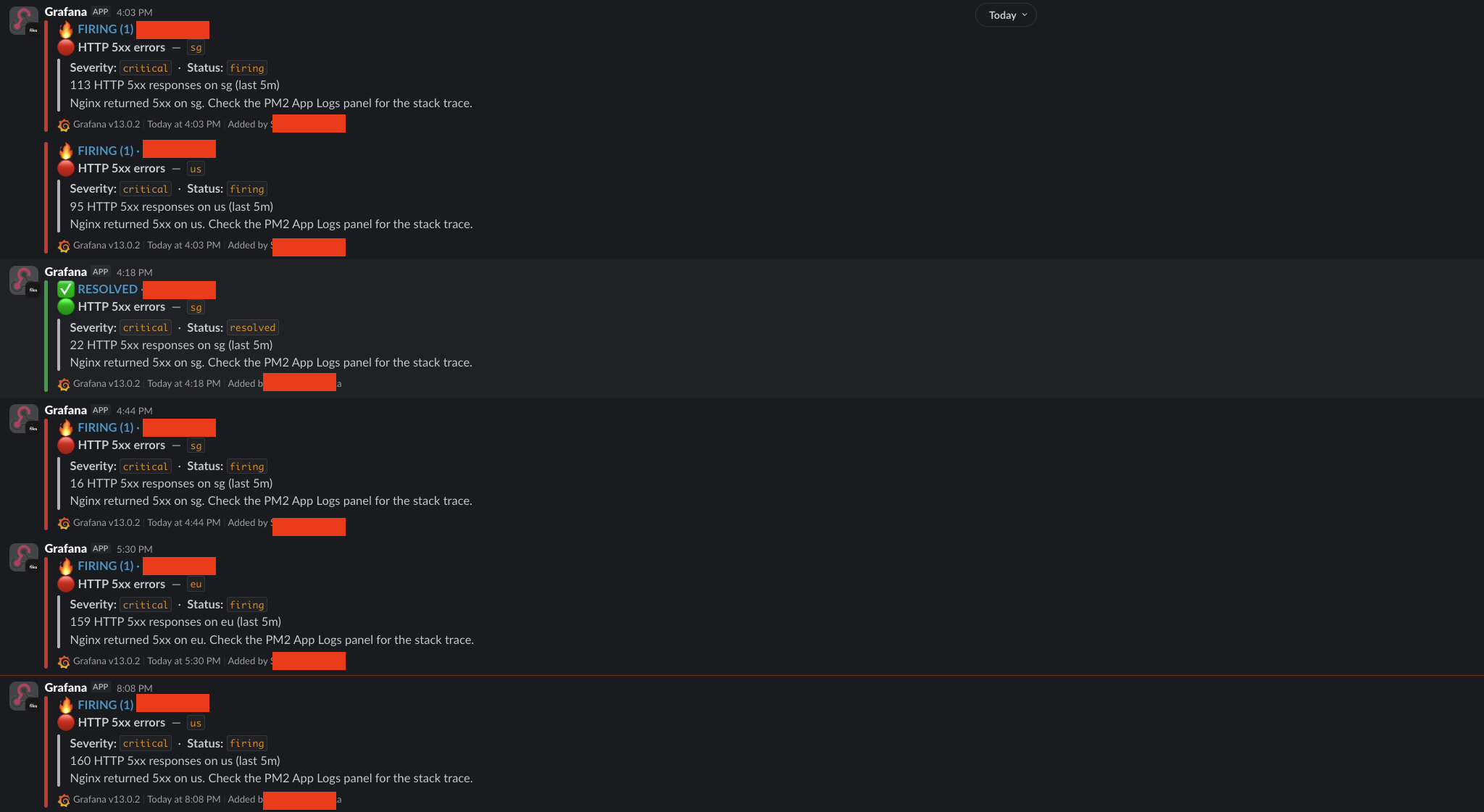
Itu kejadian beneran pas aplikasi saya mulai lempar error HTTP 5xx. Tiap pesan ngasih tau server mana, masalahnya apa, dan nunjukin log mana yang harus dicek. Saya tau detik itu juga, di mana pun saya berada, walaupun seharian itu saya nggak buka satu dashboard pun.
Inilah balikan dari artikel sebelumnya yang kepraktekan. Di AWS, sistemnya ngawasin diri sendiri dan saya bayar buat itu. Sekarang saya bikin sendiri si pengawasnya, jalan gratis, dan dia colek pundak saya begitu ada yang nggak beres.
Kenapa Saya Lebih Suka Ini Daripada CloudWatch
Jujur ya, ini bukan ajang pamer "yang gratis ngalahin yang bayar". CloudWatch itu beneran bagus dan nyaris nggak butuh usaha. Kalau lo di AWS, ya pakai aja.
Tapi buat situasi saya, setup ini menang di beberapa hal yang nyata:
- Gratis. Nggak ada biaya per metrik, nggak ada tagihan yang naik makin banyak yang dipantau. Mantau semuanya biayanya sama kayak mantau nggak ada apa-apa.
- Semua di satu tempat. Semua region, angka sama log barengan, dalam satu layar. CloudWatch selalu maksa saya loncat-loncat.
- Saya paham sepenuhnya. Tiap bagian saya bikin sendiri, jadi pas ada yang aneh sama monitoring-nya sendiri, saya tau persis harus ngecek di mana. Nggak ada kotak hitam.
- Nggak ngiket ke AWS. Kalau besok saya pindah provider lagi, seluruh setup monitoring ini ikut, nggak berubah. Dia nggak peduli servernya tinggal di mana.
Yang terakhir itu jagoan diam-diamnya. Monitoring saya nggak nikah sama cloud mana pun. Punya saya sendiri.
Pelajaran Aslinya, Sama Kayak Kemarin
Kalau lo udah baca artikel sebelumnya, lo udah tau ini mau ke mana.
Cara yang mahal dan serba-diurusin itu nggak salah. Pas saya punya sejuta user dan bos yang nggak peduli biaya, bayar AWS buat ngawasin semua itu pas banget. Saya bakal ngelakuin lagi.
Tapi begitu situasinya berubah, jawaban yang benar juga ikut berubah. Saya pindah dari "biar AWS yang ngawasin" ke "saya ngawasin sendiri", dan persis kayak waktu pindah server, hadiahnya bukan cuma duit yang kehemat. Tapi akhirnya paham sistem sendiri, dari atas sampai bawah.
Nggak ada kotak hitam lagi. Pas ada yang rusak, saya nggak buka tiket support terus nunggu. Saya buka dashboard sendiri, baca log sendiri, terus benerin. Rasa itu lebih berharga dari duit yang saya hemat.
Kalau ada yang mau saya bahas lebih dalam, mau config Prometheus-nya yang detail, cara saya nyambungin alert ke chat, atau dashboard Grafana-nya sendiri, tinggal bilang aja. Saya seneng nulis panduan langkah demi langkahnya sebagai lanjutan.
Sekarang coba cek server lo sendiri. Dan mungkin tanya ke diri sendiri: lo beneran tau servernya baik-baik aja sekarang, atau cuma berharap? 🚀